

Comparing GitHub’s REST and GraphQL APIs
As part of my day job we scrape data about the IBM GitHub organization (github.com/ibm). We just moved from using GitHub’s REST API to their GraphQL API. Our application was running fine until the number of repos under the IBM org started to grow, at that point we started to hit REST API limits. GitHub allows authenticated users to have 5000 API calls per hour. With over 1500 repos we were hitting that limit very easily. To mitigate this we ended up checking the Rate Limits and sleeping for small chunks of time. However, once our organization hit 2000 repos we started to hit the limits of our Travis CI job, which capped jobs at 90 minutes. It was time for a new approach.
About GraphQL
For the uninitiated, here’s the definition of GraphQL from Wikipedia:
GraphQL is an open-source data query and manipulation language for APIs. … It allows clients to define the structure of the data required, and the same structure of the data is returned from the server, therefore preventing excessively large amounts of data from being returned.
In my point of view, it basically acts as a super-powered version of a traditional GET REST call. From a client point view, you can specify all the data you want upfront. By leveraging the relationships between the sets of data in the backend, the data can be fetched much more quickly and in fewer API calls.
One of the best way to wrap your head around these concepts is to use GraphiQL. GraphiQL is an in-browser IDE that quickly allows users to query a GraphQL backend. GitHub’s GraphQL API Explorer is an example of GraphiQL and is available to try for free, you just need to login. See the screenshot below for a quick example.
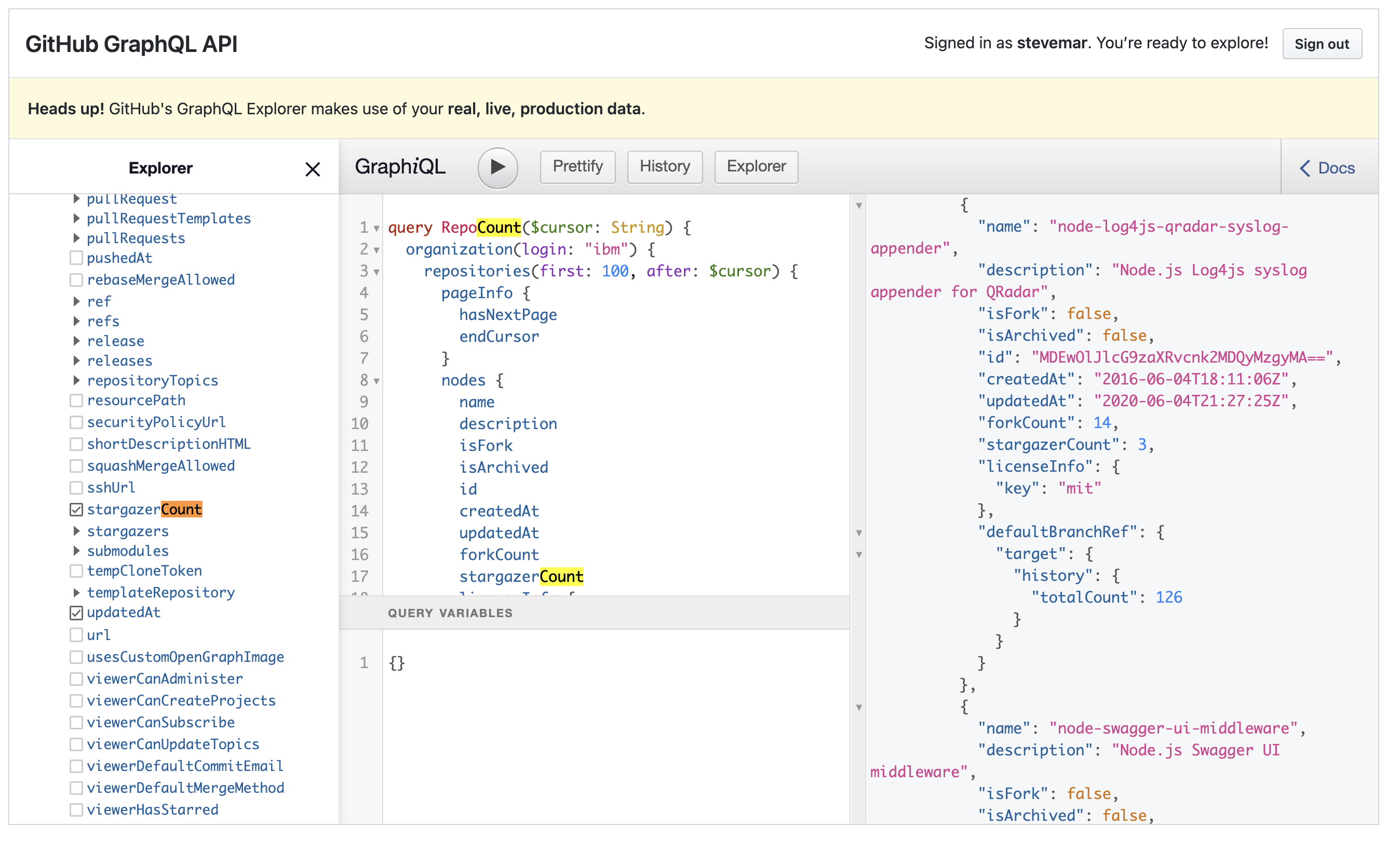
GraphQL vs REST
Since we’re comparing the two, let’s document a few things here. Our application is Python based so we’re only looking at Python based implementations.
| REST | GraphQL | |
|---|---|---|
| GitHub API | https://api.github.com | https://api.github.com/graphql |
| Python client | https://pypi.org/project/PyGithub | https://pypi.org/project/gql |
| Client source code | https://github.com/PyGithub/PyGithub | https://github.com/graphql-python/gql |
| Client documentation | https://pygithub.readthedocs.io/en/latest | https://gql.readthedocs.io/en/v3.0.0a6 |
Using REST APIs
As mentioned above, our application initially used the PyGithub library. Our code looked similar to what is shown below. We wanted to fetch some data about each repo (does it had a license file? when was it last updated? is it a fork? etc.). You can also see my half-baked approach to working around the rate limiting problem.
Sample usage with PyGithub
from github import Github
from github import RateLimitExceededException
GH_TOKEN = os.environ.get('GH_TOKEN')
g = Github(GH_TOKEN)
repos = g.get_organization('ibm').get_repos()
all_repos = []
for idx, repo in enumerate(repos):
rate = g.get_rate_limit()
if (rate.core.reset.timestamp() - datetime.utcnow().timestamp()) < 0:
print('API limit should have reset but has not, sleeping for 2 minutes')
time.sleep(120)
elif rate.core.remaining == 0:
print('No more API calls remaining, sleeping for 5 minutes')
time.sleep(300)
elif rate.core.remaining < 1000:
print('Slowing down. %s API calls remaining, sleeping for 30 seconds' % rate.core.remaining)
time.sleep(30)
entry = {}
entry['name'] = repo.name
entry['description'] = repo.description
entry['fork'] = repo.fork
collaborators = [ x.login for x in repo.get_collaborators() ]
collaborators = sorted(list(set(collaborators)))
entry['collaborators'] = collaborators
commits = repo.get_commits()
last_modified = commits[0].last_modified
entry['last_modified'] = last_modified
try:
entry['license'] = repo.get_license().license.key
except:
entry['license'] = None
all_repos.append(entry)
print('Total repos discovered')
print(len(all_repos))
print('First repo data')
print(all_repos[0])
Output with PyGithub
Not seen in the code is where I added a breakpoint to the loop to stop at 50 repos. I timed the application with the time command and to get information for just 50 repos it clocked in at just under 30 seconds. Getting data for all 2100+ repos would be about 1200 seconds or 20 minutes. Note that every additional attribute you want to discover, like finding if something has a README file, would effectively multiply your time by the number of repos. Not great for scaling!
$ gtime python snippets/github-rest-api.py
Total repos discovered
50
First repo data
{'name': 'ibm.github.io', 'description': 'IBM Open Source at GitHub', 'fork': False,
'collaborators': ['IBMCode', 'stevemar'], 'last_modified': 'Wed, 15 Jan 2020 16:32:44 GMT',
'license': 'mit'}
1.33s user 0.19s system 5% cpu 29.38 total
Using GraphQL
This time we would use the gql library. Our code looked similar to what is shown below. The query was tested using GitHub’s GraphQL explorer before dropping it into our application. Two quick notes about using this library.
If you’re using the popular zsh shell, you’ll need to install it with single quotes, like this:
pip install 'gql[all]', because of this issue.To get our example working, we had to use the
requeststransport layer.
In terms of readability, I find using gql a bit more complicated. You’re also limited to returning, at most, 100 entries at time. You can see how I handle looping through the data with the cursor parameter and waiting until the hasNextPage attribute comes up empty.
Sample usage with gql
from gql import gql, Client
from gql.transport.requests import RequestsHTTPTransport
GH_TOKEN = os.environ.get('GH_TOKEN')
transport = RequestsHTTPTransport(url="https://api.github.com/graphql",
headers={'Authorization': 'token ' + GH_TOKEN})
client = Client(transport=transport)
def get_repos(params):
# define the gql query
query = gql(
"""
query RepoCount($cursor: String) {
organization(login: "ibm") {
repositories(first: 100, after: $cursor) {
pageInfo {
hasNextPage
endCursor
}
nodes {
name
description
isFork
updatedAt
licenseInfo {
key
}
}
}
}
}
"""
)
response = client.execute(query, params)
return response
all_repos = []
endCursor = None
while True:
params = {"cursor": endCursor}
response = get_repos(params)
repos = response['organization']['repositories']['nodes']
all_repos = all_repos + repos
hasNextPage = response['organization']['repositories']['pageInfo']['hasNextPage']
endCursor = response['organization']['repositories']['pageInfo']['endCursor']
if not hasNextPage:
break
print('Total repos discovered')
print(len(all_repos))
print('First repo data')
print(all_repos[0])
Output with gql
This was much faster. To get information for all 2100+ repos, it clocked in at just under 8 seconds!!
$ gtime python snippets/github-graphql-api.py
Total repos discovered
2177
First repo data
{'name': 'ibm.github.io', 'description': 'IBM Open Source at GitHub', 'isFork': False,
'updatedAt': '2021-07-26T16:08:08Z', 'licenseInfo': {'key': 'mit'}}
0.36s user 0.14s system 6% cpu 7.398 total
Summary
While some things are still easier to get using the REST API, like collaborators, reading 2100 repos in 8 seconds compared to 50 repos in 30 seconds is a no-brainer change to make.